[1주차] JVM은 무엇이며 자바 코드는 어떻게 실행하는 것인가.
목표 - 자바 소스 파일(.java)이 JVM으로 실행되는 과정을 이해해보자!
본 게시글은 도서 <Java in a Nutshell>, <윤성우의 열혈 Java 프로그래밍> , 웹 페이지 <www.guru99.com>등을 참고하여 작성하였습니다.
제가 직접 그린 이미지가 아닌, 인터넷에서 참조한 이미지 파일의 출처는 이미지 파일 바로 하단에 적어두었습니다.
[ JVM이란 무엇인가? ]
JVM = Java Virtual Machine
그렇다.
JVM은 Java Virtual Machine의 약자로, 이를 직역하면 "자바 가상 머신"이 되겠다.
그렇다면, 이 JVM이 하는 일은 무엇이며, 왜 존재 하는지에 대해 알아보겠다.

위 구조는 익히 알고 있듯, 일반적인 프로그램의 실행구조이다.
프로그램과 하드웨어 사이에 시스템 소프트웨어인 운영체제가 존재하고, 이 운영체제는 응용 프로그램의 하드웨어 자원(메모리 등)사용을 관리하고, 여러 프로세스를 스케줄링하여 여러개의 프로세스가 동시에 수행되는 것처럼 보이게 만들기도 한다. 즉, 프로그램과 하드웨어 사이의 중개인과 같다.

위 구조는 방금 본 일반적인 프로그램의 실행구조와 같은 듯 다른, 자바 프로그램의 실행 구조이다.
프로그램과 운영체제 사이에 자바 가상 머신이 존재하고 있다. 운영체제 입장에선 위 사진과 아래 사진 둘다 별 다를 것 없이 느껴질 것이다. 즉, JVM도 운영체제 입장에선 일종의 응용프로그램과 같기 때문이다.
그렇다면 JVM은 무슨 일을 하길래 그 사이에 존재하게 된 걸까?
운영체제가 프로그램과 하드웨어 사이의 중개인 역할을 했듯, JVM은 프로그램과 운영체제 사이의 중개인 역할을 한다. 즉, 프로그램의 실행 시키는 운영체제의 종류에 상관 없이 같은 자바 프로그램이 실행될 수 있도록 한다. 예를 들어, 리눅스 운영체제와 윈도우 운영체제 위에서 돌아가는 일반적인 프로그램의 경우, 운영체제에 따라 프로그램을 실행시키는 과정에 차이가 있기 때문에 같은 기능을 하는 프로그램이어도 다른 코드 혹은 언어로 프로그램을 구현해야 한다.
하지만 자바 프로그램의 경우, 핸드폰 케이스를 갈아 끼우듯 각 운영체제에 맞는 JVM을 갈아 끼우면 다른 운영체제 상이라고 할 지라도 같은 코드의 프로그램을 실행시킬 수 있게 된다. 리눅스 운영체제라면 리눅스 JVM, 윈도우 운영체제라면 윈도우 JVM이 존재하여 같은 프로그램을 실행시킬 수 있다는 것이다. 셋탑 박스, 블루레이 플레이어부터 더 큰 메인 프레임들도 그에 맞는 JVM을 갖추고 있다.
즉, JVM은 본인의 희생(?)으로 자바 프로그램의 구현을 운영체제로부터 자유롭게 해준다.
"Write Once, Run Anywhere(WORA)"
[ 자바 파일을 컴파일 하는 과정 & 자바 파일을 실행하는 과정 ]
일단 자바 프로그램은 실행시키면 JVM에게 전달된다는 것은 알겠다.
그렇다면 내가 작성한 자바 프로그램은 어떤 과정을 거쳐 JVM에게 전달되고, 실행되는 것일까?
자바 프로그램은 아래와 같은 명령어로 시작된다:
java <arguments> <program name>
프로그램을 본격적으로 실행하기 앞서, JVM은 내가 작성한 자바 프로그램을 들이밀어도 무슨 소린지 모를 것이다. JVM이 이해할 수 있는 형태와 내가 작성한 형태는 다르기 때문이다. (자바 프로그램은 한국어를 쓰는데, JVM은 일본어를 쓰고 있어서 소통이 안된다고 생각하면 쉽다.)
이 때, JVM이 내가 작성한 자바 코드를 이해할 수 있도록 코드를 변환해주는, JVM과 자바 프로그램 사이의 숨은 중재자가 등장한다. 바로 '컴파일러'이다.
자바 컴파일러는 자바 소스파일의 코드를 JVM이 이해할 수 있는 형태로 바꿔주는 프로그램이다. 자바 컴파일러의 구체적인 이름은 'Java.exe'라고 하는 자바 런처이다. 이 자바 컴파일러는 JVM 위에서 자바 프로그램이 실행되면 이를 JVM이 알아듣는 형태로 변환하여 전달해준다.
여기서 JVM이 이해할 수 있는 형태란 '자바 바이트 코드'를 뜻한다. 자바 '바이트' 코드라고 불리우는 이유는, 자바 컴파일러가 변환해준 명령어의 크기가 1바이트이기 때문이다. (->잠시 후에 구체적으로 설명할 것이다.)
자바 바이트 코드를 넘겨받은 JVM은 운영체제처럼 프로그램이 실행되는데 필요한 런타임 환경을 마련하여 프로그램을 실행시킨다. JVM은 프로그램을 실행시킬 때, 프로그램을 효율적으로 실행시키기 위해 런타임 정보를 수집한다. 즉, JVM은 그 위에서 실행되는 프로그램을 모니터링하고 최적화시키는 것이다. 그렇기에 자바 프로그램은 부분 부분마다 호출되는 횟수가 다르다. 일례로, JVM중 하나인 HotSpot JVM은 프로그램에서 가장 많이 호출되는 부분, 일명 "핫 메소드"를 찾아낸 후, 이를 바로 기계코드로 컴파일해낸다. (JVM을 위한 자바 컴파일러의 컴파일이 아닌, JIT 컴파일러를 이용해 하드웨어를 위한 컴파일을 바로 실행한다는 뜻) 이렇게 실행 시간을 줄여 성능을 높이는 것이다.

자바 프로그램 이미지 - www.flaticon.com/freeicon/file_3143478term=java&page=1&position=13&related_item_id=3143478
톱니바퀴 이미지 - www.flaticon.com/search?word=cog%20wheel
바이트코드 이미지 - www.researchgate.net/figure/1-Comparison-of-CIL-and-Java-Bytecode_tbl1_248510301
[ 바이트코드란 무엇인가? ]
자바 프로그램이 자바 컴파일러에 의해 자바 바이트 코드로 변환되기에, 이를 기계가 아는 머신코드라고 이해하기 쉽다. 하지만 엄연히 말하자면 바이트코드와 머신코드는 다른 것이다. 머신코드는 CPU를 위한 언어이며, 바이트코드는 JVM을 위한 언어이다. 즉, 자바 소스코드의 머신 코드 사이의 중간 언어인 것이다. 마치 한국인과 외국인의 중간에서 소통을 돕는 통역가와 비슷한 맥락이다. 바이트코드(클래스 파일)는 자바 소스코드와 달리 사람이 읽을 수 없다.
바이트 코드는 그 크기가 1바이트 이기 때문에, 8비트로 이루어졌고, 2^8 = 256개의 명령어를 표현할 수 있다. 하지만 모든 명령어가 쓰이는 것은 아니고, 이 중 200개 정도가 사용된다.
[ JIT 컴파일러란 무엇이며, 어떻게 동작하는가? ]
또 다른 컴파일러가 등장했다. 그이름은 JIT...
JIT = Just In Time
방금 봤던 자바 컴파일러와 같은 듯 다른 녀석이다. 방금 JVM의 성능 최적화에서 잠시 얼굴을 비췄을 때 예상했듯,어쨌든 이 녀석도 컴파일러이기에 어떤 언어를 다른 언어로 변환해주는 역할을 하긴 하지만, 그 대상이 다르다.
일단 그 이름에서 역할을 유추해보자.
Just In Time -> 파파고에 돌리니 '마침 좋은 때에' 라는 직역이 나온다 ㅋㅋ 뭔가 시간을 줄여 준다는 느낌을 받는다. 이 글을 정독하신 분은 기억 하실 것이다. 방금 JVM이 실행시간을 줄이기 위해 핫 메소드 코드를 실행시킬 땐 자바 컴파일러를 거치는 과정을 생략하고 바로 머신코드로 바꾸는데, 이 때 JIT 컴파일러가 사용된다.
즉, 자바 컴파일러가 자바 소스코드를 자바바이트코드로 변환하고 이를 JVM에 전달했다면, JIT 컴파일러는 자바 바이트코드를 머신코드로 바꾸고 이를 OS에 전달해준다. 자바 컴파일러에 이어 JIT 컴파일러가 등장해 자바 소스코드를 두 번 전환해주게 되는 것이다.
JIT 컴파일러의 컴파일 과정은 자바 컴파일러의 컴파일 과정과 다르게 JVM의 프로그램 실행 중 일어나는 것이므로, 컴파일 시간(compile time)이 아닌 실행시간(run time)에 일어나게 된다.

머신코드 이미지 - marketbusinessnews.com/financial-glossary/machine-code/
자바 프로그램의 실행 과정을 컴파일 타임과 런타임을 합해서 한 번에 표현하면 다음과 같다!

이미지 파일 출처 - aboullaite.me/understanding-jit-compiler-just-in-time-compiler/
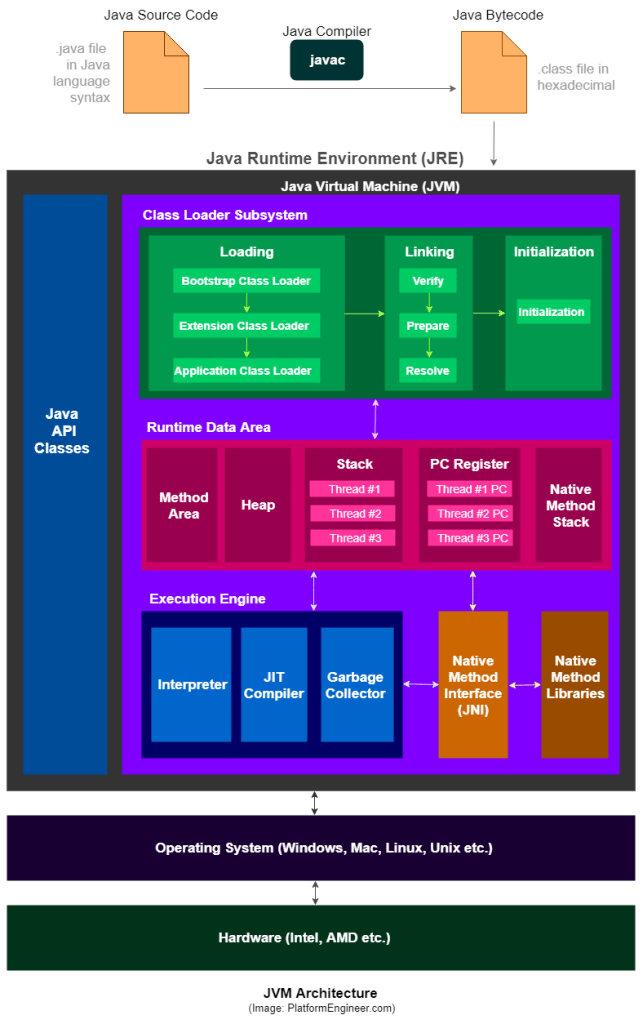
[ JVM의 구성 요소 ]
방금전 까지 컴파일 타임과 런 타임에 따른 자바 코드의 실행과정을 살펴보았다. 사람이 직접 친 자바 소스코드는 자바 컴파일러에 의해 바이트코드로 변환되어 JVM에 전달되고, 해당 바이트코드는 JIT 컴파일러에 의해 머신코드로 변환되어 운영체제에 전달된다. 여기서 알아볼 수 있는 것은 JIT 컴파일러도 JVM의 일부에 속한다는 것이다.
머신코드로의 변환 외에도 JVM의 임무는 다양하다:
1. 곧 실행될 자바코드의 컨테이너 역할을 한다
2. 안전하고 신뢰할 만한 실행 환경을 제공해주어 자바 코드를 실행시킨다.
3. 메모리 관리를 진행한다.
4. 플랫폼에 구애받지 않는 (cross-platform) 실행 환경을 제공한다.
JVM은 이 임무들을 모두 JRE 환경(Java Runtime Environment, 어플리케이션이 실행 중)에서 수행하며, 임무를 모두 수행하기 위해 JVM은 다음과 같이 구성된다.

Class Loader: 2. 안전한 환경 제공, 3. 메모리 관리 시행
'곧 실행될 자바 코드' 란 자바 컴파일러에 의해 생성된 '클래스 파일'을 의미한다. 이 클래스 파일을 로딩해오는 것 또한 JVM의 역할일 것이다. RAM에 상주하고 있는 JVM의 Class Loader가 런타임동안 클래스 파일을 찾아서 동적으로 이를 메모리에 할당하여, 로딩해온다. 로딩해오는 것에서 끝나는 것이 아니고, 클래스 변수 초기화, 클래스를 구성하는 데이터, 이미지 등의 리소스를 찾기도 한다. 클래스 로더는 한번에 모든 클래스를 불러오는 것이 아니라, 어플리케이션의 호출이 있을 때 JRE에 의해 불러온다. 결과적으로 메모리에 클래스가 로딩되고, 초기화되게 된다.
클래스 로딩의 과정을 구체적으로 살펴보면 다음과 같다.
1) Loading: 클래스 파일 ->클래스 오브젝트 / 뼈대를 만드는 과정
클래스 파일의 바이트코드 들을 바이트 배열로 로딩한다. 그 후, 클래스 파일을 클래스 오브젝트로 변환한다.
이 과정동안 defineClass() 메소드로 로딩하고자 하는 클래스 오브젝트의 뼈대를 만든다. 이 때, 내부의 값이 바뀌어선 안되는 상수(constant)가 일정한지 체크하는 과정도 거친다. 아직 완전한 클래스 오브젝트가 만들어진 상태는 아니기에, 다음 과정들(2, 3, 4)에서 클래스가 linking(클래스 파일들이 엮이는 것) 되는 과정을 거쳐야 완벽한 클래스 오브젝트가 만들어진다.
2) Verification: 보안에 취약한 코드를 찾는 과정
클래스 파일들이 JVM의 보안 모델을 위반하지 않는지 확인한다. 바이트 코드들은 대부분 정적으로 확인할 수 있으므로, 이 과정이 클래스 로딩의 과정을 더디게 하지만, 런타임에서 따로 체크할 필요가 없으므로 시간을 줄여준다. (JVM의 보안 모델과 관련해선 구체적으로 다음에 알아보겠다 ㅎㅎ ..)
이 때 JVM의 바이트 코드를 실행시킬 때 충돌되거나, undefined, untested 상태가 되는 것을 막을 수 있다. 상태가 undefined 되고나 untested 될 경우, 악의적인 공격에 취약할 수 있다. 이는 자바 컴파일러가 바이트 코드를 잘못 생성해냈거나, 악의적으로 자바 코드를 직접 짰을 경우 벌어질 수 있는 일들이다.
3) Preparation and Resolution: 메모리 할당, 클래스 파일 타입 확인 (초기화 전 최종 점검)
이제 확인할 것들(상수, 보안 등)은 다 확인했으니, 메모리가 할당(JVM Memory)되고 클래스의 정적 변수들은 초기화를 할 준비가 되었다. 이 과정에서 클래스 파일의 타입이 런타임에 잘 전달되었나 확인하고, 만약 전달되지 않았다면 클래스 로딩(1번 항목)을 다시 실행해서 클래스 파일의 타입을 로딩해온다. 이 과정을 모든 타입이 로딩될때까지 반복한다. 이로서 클래스 파일들이 서로 엮이게 된다.
4) Initialization
JVM 은 이제 클래스를 초기화한다. 정적 변수, 정적 초기화 블록들(바이트코드)이 실행된다. 정적 블록들이 다 실행되었다면, 클래스가 다 로딩되었다고 볼 수 있다.
또한 클래스의 로딩의 과정은 서로 다른 클래스 로더의 작용으로 구성된다. 클래스 로더의 종류는 세 가지로, Bootstrap class loader, Extensions class loader, System class loader가 있다. 이 순서대로 클래스 파일이 로딩된다.
JVM Memory: 1. 자바 코드의 컨테이너, 3. 메모리 관리 시행
방금 언급했듯이, JVM 은 호스트 OS 메모리의 RAM에 상주하고 있다. 하지만 JVM은 런타임 데이터, 컴파일 된 코드 등을 저장하기 위해 여러개의 저장공간으로 분할되어있다. 이 저장공간들은 다섯종류로 나뉜다.
1) Method Area
JVM이 클래스 파일을 넘겨받고 가동을 시작하면서(==런타임의 시작)생성되는 공간으로, 컴파일된 코드(바이트코드), 메소드, 그 데이터와 필드를 저장한다. 컴파일 시간 때 정의된 리터럴(어떤 변수를 초기화시킬 때 사용, 즉시값이라고도 불림), 레퍼런스(주소값 - 클래스, 인터페이스, 배열 등의 실제 객체 주소)가 담겨있다. JVM이 알아서 적당한 위치에 메모리를 할당하는데, 만약 런타임중(확실X) 공간이 더 필요하다면 더 커질 수 있다.
2) Heap
힙엔 JVM이 가동될 때, 즉 런타임이 시작될 때 생성된 객체들이 저장된다. 힙은 크게 세 세대, Young Generation(젊은 세대), Old Generation(늙은 세대), Permanent Generation(영구 세대)로 나뉜다. 객체들은 생성된 이후의 시간(쉽게 말하면 나이...)에 따라 알맞은 영역에 배정되어 저장된다. 또한, 각 세대들은 구체적으로 이렇게 나뉜다.

객체들은 다음과 같은 과정으로 Heap에서 이동한다
: Eden ->S0 -> S1 -> Old
젊었던(Young) 객체들은 생성과 동시에 Eden 공간에 저장된다. 이 후 몇 번의 쓰레기 청소(Garbage Collection - JVM이 메모리가 부족할 때 객체들을 삭제하여 메모리를 정리하는 것, 후에 자세히 설명할 예정)에 살아남은 객체들은 살아남은 객체들을 위한 공간인, Survivor Space에 저장되고 그 안에서도 S0, S1의 순서로 늙어간다. 만약 객체가 그 이후에도 없어지지 않고 살아남게 되면, 늙은(Old) 객체가 된다.(음 졸업하고 아너스 클럽 뭐 그런 곳에 가입되는 거라 생각하면 될까.) 영구 세대엔 모든 정적, 인스턴스 변수들의 이름과 그 값이 쌍으로 저장되어 있다.(레퍼런스의 경우 객체 이름 - 주소값)
3) JVM Language Stacks
4) PC(Program Counter) Registers
5) Native Method Stacks
Execution Engine:
1) JIT Compiler
2) Garbage Collector
C에서 동적 할당을 쓸 때, 메모리 할당을 해제해주는 free()함수를 항상 프로그램 종료시에 써줘야 했다. TMI지만 free() 함수를 쓰지 않으면 감점당하기도 했다.ㅋㅋ 하기 때문이다. 하지만 자바에선 C에서와 같이 free()를 꼬박꼬박 호출해줄 필요가 없다. 바로 이 Garbage Collector(줄여서 'GC')가 존재하기 때문이다.
Native Method Interface, Native Method Libraries
이미지 출처
medium.com/platform-engineer/understanding-java-memory-model-1d0863f6d973
참고한 사이트
dzone.com/articles/java-virtual-machine-internals-class-loader
hackthejava.wordpress.com/2015/01/09/memory-architecture-by-jvmruntime-data-areas/